Let’s start with these definitions:
Zero-level set: is a mathematical function, e.g. \( x^2 + y^3 + z – 2 = 0 \) is a level-set.
Neural Implicit Representation: we represent a 3D shape’s surface using a mathematical formula. This formula is called zero-level set where the formula is zero if we are on the 3D shape, and some other value if we are on a different location in the space.
Neural implicit representations simply parameterizes this zero-level set using MLPs. So, we don’t need to write a function to model 3D shape, but we learn it using a neural network. However, this requires 3D supervision such as 3D point cloud.
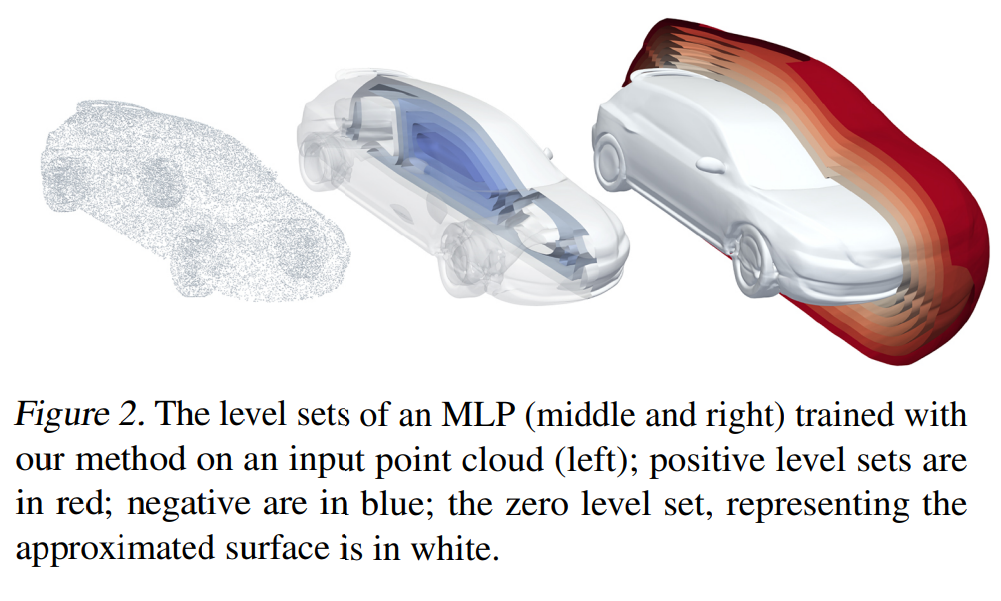
Q: Can we learn these parameters without 3D supervision?
Differential volumetric rendering (DVR) is very useful here. Assume we have an image and we know camera location and direction. We try to minimize error by projecting 3D generated model to 2D image which we already observed. (??? more details needed like how do we know the camera parameters etc.)
Better? NeRF
Neural radial fields idea is to model the scene using neural network, and depending on the camera position and direction, sample pixels from the scene. It requires more than an image (usually around 50 of them) to learn the scene. TODO: more information/explanation needed
References
[1] Implicit Geometric Regularization: https://arxiv.org/pdf/2002.10099.pdf
[2] DVR: https://arxiv.org/pdf/1912.07372.pdf